

Recentemente comecei a criar alguns scripts para coleta de páginas e mineração de dados, minha necessidade tem sido coletar e agrupar dados de diversas fontes, estruturar e padronizar para realizar buscas complexas.
Hoje vou compartilhar como criar um web scraping, um tutorial prático para você começar a construir seus spiders.
É importante reforçar que existem diversos métodos mais avançadas para construir estes mecanismos, este tutorial vai lhe ajudar a dar o primeiro passo.
Alguns avisos
Quando começamos a construir scrapers e entendemos como extrair inteligência com os dados coletados, é tentador o que podemos fazer. Existem diversas utilidades para este tipo de aplicação, desde analise de reviews de usuários em serviços, analise de sentimentos, analise de produtos, analise de preços e processos judiciais, como o caso do Jusbrasil.
O espectro de possibilidades é muito grande, porém está prática pode ser considerada errada por alguns sites, dependendo da frequência que você acessar as fontes, você pode ser bloqueado.
Também vale lembrar que foi aprovado recentemente no Brasil uma lei para proteção de dados dos usuários, verifique aqui se a sua ideia pode sofrer algum impacto. Em outros países também existem leis similares, fique atento.
Portanto, antes de você iniciar a construção do seu projeto, certifique-se sobre o tipo de informação que vai coletar e tenha certeza de estar obtendo de fontes públicas. Utilize de forma responsável, você pode ser responsabilizado por isto.
Definindo o objetivo
Neste exemplo, vamos fazer um scraper para coletar anúncios de produtos no Mercado Livre, quero fones de ouvido beats original, vamos encontrar as melhores ofertas anunciadas. Estou partindo de uma url de resultado de busca.
Cabe lembrar que o Mercado Livre tem APIs para acesso a recursos e funções mais completas, se você precisa criar algo realmente profissional, consulte a API.
A URL que vamos usar neste tutorial:
Desta página quero obter os seguintes dados de produto: Nome, Preço, Frete e URL. Com isto eu já consigo organizar a minha lista e descobrir o menor preço. <3
Escolhendo Request e Cheerio
Para este tutorial escolhi as seguintes bibliotecas:
Request – Serviço http para a acessar as páginas.
Cheerio – API similar ao jQuery para nos ajudar a extrair o conteúdo via seletores.
Sequelize – ORM para manipular o MySQL.
MySQL2 – Client MySQL para realizar a conexão.
Babel CLI – Para o transpiler do nosso código ES6.
Adicionando as dependências
Vamos criar nosso package e adicionar as dependências:
npm init
npm install request cheerio sequelize mysql2 dotenv babel babel-cli --save
npm install babel-preset-env --save-devAdicionando as tabelas na sua base MySQL
Estou considerando que você já tem o MySQL instalado. Crie uma base com o nome que preferir e execute o script:
CREATE TABLE `pages` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`url` text NOT NULL,
`read` tinyint(1) NOT NULL DEFAULT '0',
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`deleted_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`)
)
CREATE TABLE `products` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL DEFAULT '',
`price` decimal(10,2) NOT NULL,
`shipping` varchar(100) DEFAULT '',
`url` text NOT NULL,
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`deleted_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`)
)Definindo nossas configurações
Vamos criar nossos arquivos de configurações, os primeiros serão nossas models para manipular nossa base. Crie o arquivo pages.js e products.js dentro do diretório models, na raiz do app.
No arquivo pages.js defina o schema da seguinte forma:
export default (sequelize, DataType) => {
const Pages = sequelize.define(
'pages', {
id: {
type: DataType.INTEGER,
autoIncrement: true,
primaryKey: true,
},
url: {
type: DataType.TEXT,
required: true,
},
read: {
type: DataType.BOOLEAN,
default: false,
},
},
{
tableName: 'pages',
},
);
return Pages;
};E no arquivo products.js escreva o schema assim:
export default (sequelize, DataType) => {
const Products = sequelize.define(
'products', {
id: {
type: DataType.INTEGER,
autoIncrement: true,
primaryKey: true,
},
productML: {
type: DataType.STRING(100),
required: true,
},
name: {
type: DataType.STRING(100),
required: true,
},
price: {
type: DataType.STRING(100),
required: true,
},
shipping: {
type: DataType.STRING(100),
required: true,
},
url: {
type: DataType.TEXT,
required: true,
},
},
{
tableName: 'products',
},
);
return Products;
};Estes arquivos são responsáveis por montar o schema da nossa tabela para o Sequelize, por parâmetro estou passando o objeto sequelize e os DataTypes. Desta maneira eu consigo criar um arquivo para cada tabela e preparar meu código. Um funcionalidade interessante do sequelize é a possibilidade de criarmos hooks, eventos que são chamados em determinada ação do script.
Consulte a documentação dos hooks e veja todos o métodos disponíveis.
Agora vamos criar nossos arquivos configuração e acesso o banco. Crie o arquivo .env na raiz do seu app e o diretório config, adicione dois arquivos nele, um chamado de config.js e outro de datasource.js
O arquivo .env deve ter suas variáveis de acesso ao MySql.
DB_HOSTNAME = '127.0.0.1'
DB_USERNAME = 'tutorial'
DB_PASSWORD = 'senha'
DB_DATABASE = 'banco'O arquivo config.js vai fazer o expor das variáveis de ambiente e o que mais precisar.
require('dotenv').config();
export default {
username: process.env.DB_USERNAME,
password: process.env.DB_PASSWORD,
database: process.env.DB_DATABASE,
params: {
host: process.env.DB_HOSTNAME,
dialect: 'mysql',
},
};Nosso arquivo datasource vai inicializar o sequelize e carregar as models definidas anteriormente. Ele vai receber por parâmetro nosso config.
import Sequelize from 'sequelize';
import path from 'path';
let database = null;
const loadModels = (sequelize) => {
const dir = path.join(__dirname, './../models/');
const models = [];
const filePages = path.join(dir, 'pages');
const fileProducts = path.join(dir, 'products');
const modelPages = sequelize.import(filePages);
const modelProducts = sequelize.import(fileProducts);
models[modelPages.name] = modelPages;
models[modelProducts.name] = modelProducts;
return models;
};
export default (config) => {
if (!database) {
const op = Sequelize.Op;
const sequelize = new Sequelize(
config.database,
config.username,
config.password,
{
host: config.params.host,
dialect: config.params.dialect,
operatorsAliases: op,
logging: false,
},
);
database = {
sequelize,
Sequelize,
models: {},
};
database.models = loadModels(sequelize);
sequelize.sync().done(() => database);
}
return database;
};Criando nossas functions
Neste exemplo coloquei todas as funções no arquivo index.js, eu separei meu código em pequenas partes, criei um método main assíncrono e adicionei novas dependências para conseguir trabalhar com o async await.
Vamos adicionar as novas dependências:
npm install request-promise interval-promise --saveVamos importar nossos arquivos, bibliotecas e inicializar o sequelize.
import config from './config/config';
import datasource from './config/datasource';
import cheerio from 'cheerio';
import request from 'request-promise';
import interval from 'interval-promise';
const db = datasource(config);
const modelPages = db.models.pages;
const modelProducts = db.models.products;Agora vamos criar nossa função para retornar as últimas páginas para extração.
No meu exemplo, criei um array personalizado trazendo o id e url da página, mas é possível retornar o registro todo contendo o model page ou ate mesmo filtrar os campos desejados atribuindo na chamada do método findAll.
function getUrlsToScrape(amount) {
return new Promise((resolve, reject) => {
modelPages.findAll({
where: {
read: 0
},
limit: amount
})
.then(urls => {
var urlsToReturn = [];
for (let index = 0; index < urls.length; index++) {
urlsToReturn.push({
url: urls[index].url,
id: urls[index].id,
});
}
resolve(urlsToReturn);
})
.catch(err => {
reject(err);
})
})
}Vamos criar uma função para marcar como lida a página processada.
function updatePageScraped(id) {
return new Promise((resolve, reject) => {
modelPages.findOne({ where: { id } })
.then(urlScraped => {
urlScraped.read = true;
urlScraped.save();
resolve();
})
.catch(err => {
reject(err);
});
});
}E agora, vamos criar nossa função requestBody, ela vai acessar a url que desejamos, ler e carregar o html usando cheerio. Com isso podemos navegar no conteúdo da página por seletores, similar ao que fazemos em jquery.
Você pode consultar todos os métodos da API Cheerio aqui.
function requestBody(url) {
return new Promise((resolve, reject) => {
const options = {
url,
transform: function(body) {
return cheerio.load(body);
}
};
request.get(options)
.then(($) => {
resolve();
})
.catch((err) => {
reject(err);
})
})
}Uma vez adicionada a base do nosso método com html carregado, veja que estou passando o retorno no then com nome de $, agora vamos extrair a lista de produtos.
Uma dica para identificar o seletor correto é usar o modo Inspect do Google Chrome, com ele aberto você pode copiar o seletor ao inspecionar o html:
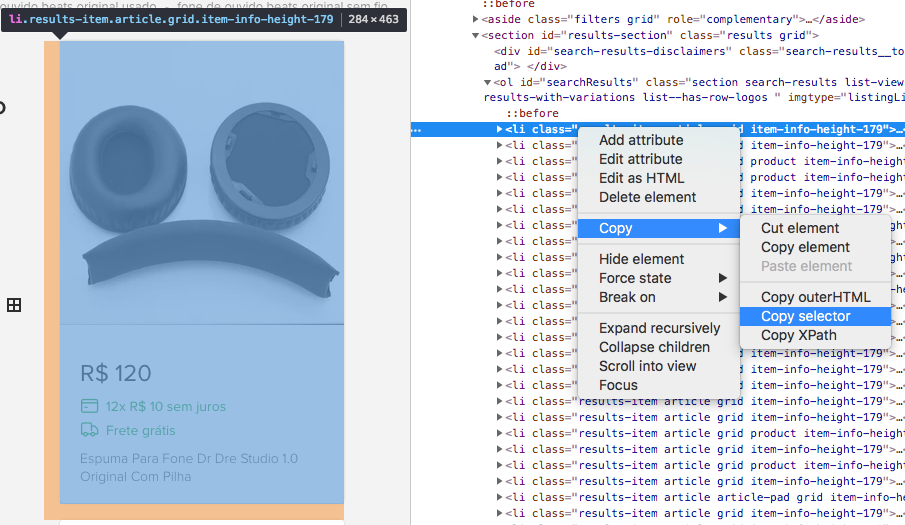
Descobrimos que o li contém algumas classes e está dentro do ul com identificador searchResults. Com isso podemos iterar na lista. Veja que o seletor ideal é:
#searchResults li.article
A seguir está o script completo. Para cada item vou extraindo o conteúdo e inserindo na minha base. Um ponto interessante no html do Mercado Livre, é que cada li contém o ID do produto, isto me ajuda a confirmar se já salvei na base anteriormente:
$('#searchResults li.article').each(function(){
var productML = $(this).find('div.rowItem').attr('id');
var url = $(this).find('.item__info-link').attr('href');
var name = $(this).find('.list-view-item-title').text();
var shipping = $(this).find('div.item__shipping > p').text();
var decimal = $(this).find('div.item__price > span.price__decimals').text();
var price = $(this).find('div.item__price > span.price__fraction').text();
price = price.replace('.', '') + (decimal != '' ? '.' + decimal : '.00');
// Verifica se a url já existe e adiciona
modelProducts.findOne({where: { productML }})
.then((product) => {
if(product == null) {
let newProduct = {
productML, url, name, price, decimal, shipping
};
modelProducts.create(newProduct);
}
})
});Feito isso, também vamos pegar as próximas urls que listam os produtos, assim toda vez que nosso método for iniciado, ele terá novas urls para ler.
$('.pagination__container > ul > li').each(function(){
const url = $(this).find('a').attr('href');
if(url != '#') {
modelPages.findOrCreate({ where: { url } });
}
});Neste caso eu utilizo o método findOrCreate do Sequelize, ele verifica se o registro existe e caso não exista já adiciona com o parâmetro da condição where. Este método tem um retorno diferente dos demais métodos, você pode consultar na documentação, mas no meu caso eu não tratei, só adicionei na base.
Agora vou adicionar minha função main e chamar usando o interval. A cada 10 segundos meu script fará o request na url.
async function main() {
try {
const pagesToScrape = await getUrlsToScrape(3);
if (pagesToScrape.length > 0) {
for (let index = 0; index < pagesToScrape.length; index++) {
const page = pagesToScrape[index];
console.log(page.url)
await requestBody(page.url);
await updatePageScraped(page.id);
console.log('Página lida com sucesso.\n');
}
} else {
console.log('Não existem novas urls disponíveis.\n')
}
} catch (error) {
console.log(error);
}
}
interval(async () => {
await main()
}, 10000)Observe que neste exemplo utilizei async await, para garantir que um próximo request seja realizado somente após o processo anterior ter sido finalizado, na minha função getUrlsToScrape estou trazendo 3 urls, mas eu poderia colocar quantas quiser e por fim, utilizei a biblioteca interval-promise, pois o setInterval não vai pausar e esperar nosso await como precisamos, esta lib resolve este problema de maneira elegante para nós.
Como nosso script depende de algum registro na base, pegue a primeira url que escolhemos como o primeiro registro na tabela pages.
Por fim, adicione o script start no seu package.json.
"start": "babel-node index.js"Agora basta digitar npm start no seu terminal para a mágica acontecer.

Este meu exemplo é básico, ainda é possível melhorar os tratamentos de erros, otimizar as funções e usar outras bibliotecas. Puppeteer ou PhantomJS são outras opções, caso você queira aprender mais.
Mas aqui está um ponto de partida para você aprender a construir um web scraper.
O código fonte deste scraper está no meu github, você baixar e usar como quiser.

E agora, dá pra melhorar?
Uma boa prática é dividir as responsabilidades dos scripts. Ter uma função só para coleta do html, outra dedicada a mineração dos dados e até o descarte. Desta forma você pode chamar as funções por serviços diferentes, ter melhor legibilidade do código, facilitar as manutenções e execuções em paralelo.
Outra boa prática é utilizar Expressões Regulares para extrair os dados do HTML, para isto recomendo o livro Expressões Regulares, uma abordagem divertida, tenho aprendido muito com este livro e criado diversas ferramentas para extrair dados usando Regex, na minha página de Livros recomendados também listo outras opções.
Outra boa prática é criar funções isoladas para cada fonte de dado. Neste exemplo estamos trabalhando com uma única fonte, o html da página está estruturado, porém isto nem sempre é realidade. Talvez você precise de métodos mais elaboradas para mineração.
Outra dica, é coletar e armazenar o html puro após a execução do javascript na página, aí você vai precisar do Puppeteer. No entanto, isto pode gerar um excesso de dados armazenados, mas vai ser útil caso algo falhe. Você poderá re-processar e se tudo der certo aí sim poderá remover o registro.
Se preferir, também poderá armazenar a url que deu erro, mas em um novo acesso, o html pode mudar.
Outras maneiras de construir o crawler
Você pode desenvolver um crawler em praticamente qualquer linguagem, Python, Go, Java, PHP ou C#. Cabe encontrar as bibliotecas equivalentes.
Em breve quero recriar este tutorial em GoLang ou Python, afinal muitos crawlers são desenvolvidos com estas tecnologias. Que por sinal, oferecem uma excelente performance para processamento de dados em grande escala.
Espero ter te ajudado, qualquer dúvida ou sugestão, deixa nos comentários.
Abraço! 🙂


